Deep learning on handwritten digits¶
The MNIST (mixed National Institute of Standards and Technology) dataset (https://en.wikipedia.org/wiki/MNIST_database) is a classic data set in machine learning. To develop our intuitions about the problem, we start with a simple linear classifier and achieve an average accuracy of $80\%$. We then proceed to build a state-of-the-art convolutional neural network (CNN) and achieve an accuracy of over $98\%$.
This notebook is available on https://github.com/jcboyd/deep-learning-workshop.
A Docker image for this project is available on Docker hub:
$ docker pull jcboyd/deep-learning-workshop/:[cpu|gpu]
$ nvidia-docker run -it -p 8888:8888 jcboyd/deep-learning-workshop/:[cpu|gpu]
1. Machine Learning¶
- Machine learning involves algorithms that find patterns in data.
- This amounts to a form of inductive reasoning: inferring general rules from examples, with the view of reapplying them to new examples. Learning by example
- This symbols are labeled (yes/no) $\implies$ supervised learning problem
Murphy, Kevin P. Machine learning: a probabilistic perspective. MIT press, 2012. (Figure 1.1)
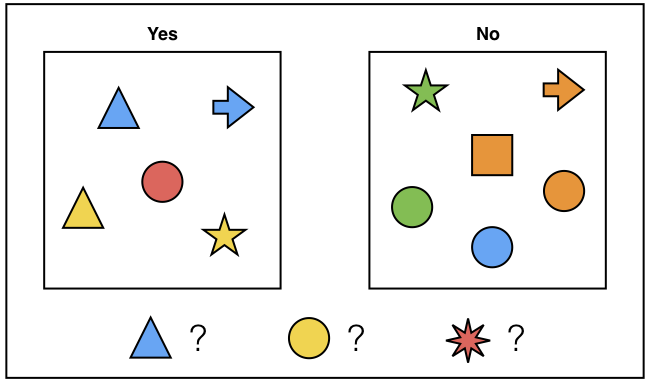
- The corresponding dataset would look something like the following:
from pandas import read_csv
read_csv(open('data/shapes.csv'))
1.1 Classifiers¶
- The above is an example of a classification problem.
- Each observation $\mathbf{x}_i$ is represented by a vector of $D$ dimensions or features and has label $y_i$ denoting its class (e.g. yes or no).
- Thus, our dataset of $N$ observations is,
- The model will attempt to divide the feature space such that the classes are as separate as possible, creating a decision boundary.
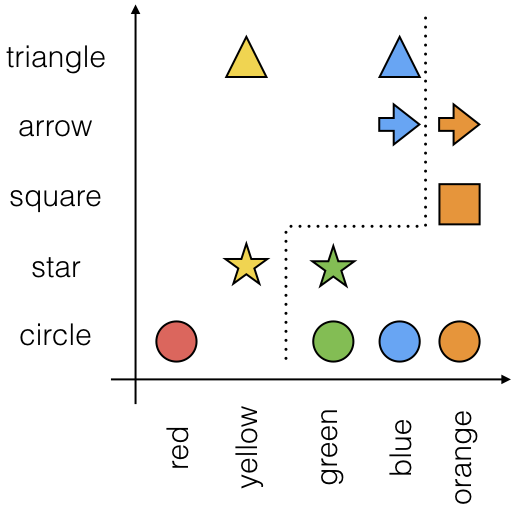
1.2 Data Exploration¶
- The MNIST dataset (https://en.wikipedia.org/wiki/MNIST_database) is a classic dataset in machine learning.
- Derived from a dataset of handwritten characters "crowdsourced" from US high school students.
- It consists of 60,000 labelled images of handwritten digits 0-9, and a test set of a further 10,000 images.
- Notably used as a benchmark in the development of convolutional neural networks.
from __future__ import print_function
from __future__ import division
import tensorflow.examples.tutorials.mnist.input_data as input_data
mnist = input_data.read_data_sets('MNIST_data', reshape=False, one_hot=False)
Xtr = mnist.train.images
Ytr = mnist.train.labels
Xval = mnist.validation.images
Yval = mnist.validation.labels
Xte = mnist.test.images
Yte = mnist.test.labels
print('Training data shape: ', Xtr.shape)
print('Training labels shape: ', Ytr.shape)
print('Validation data shape: ', Xval.shape)
print('Validation labels shape: ', Yval.shape)
print('Test data shape: ', Xte.shape)
print('Test labels shape: ', Yte.shape)
- We can visualise our data samples with Python
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
from src import vis_utils
from IPython.display import set_matplotlib_formats
set_matplotlib_formats('svg')
fig, ax = plt.subplots(figsize=(6, 6))
idx = np.random.randint(len(Xtr))
vis_utils.plot_image(ax, Xtr[idx, :, :, 0], Ytr[idx])
- As far as our model will be concerned, the images in the dataset are just vectors of numbers.
- From this perspective, there is no fundamental difference between the MNIST problem, and the symbols problem above.
- The observations just live in 784-dimensional space (28 $\times$ 28 pixels) rather than 2-dimensional space.
print(Xtr[idx].reshape((1, 784))[0])
fig = plt.figure(figsize=(8, 6))
vis_utils.plot_array(fig, Xtr, Ytr, num_classes=10)
1.3 Data Preprocessing¶
- For our linear models, we will "flatten" the data for convenience:
# First, vectorise image data
Xtr_rows = np.reshape(Xtr, (Xtr.shape[0], -1)).copy()
Xval_rows = np.reshape(Xval, (Xval.shape[0], -1)).copy()
Xte_rows = np.reshape(Xte, (Xte.shape[0], -1)).copy()
# As a sanity check, print out the shapes of the data
print('Training data shape: ', Xtr_rows.shape)
print('Validation data shape: ', Xval_rows.shape)
print('Test data shape: ', Xte_rows.shape)
- A typical procedure prior to training is to normalise the data.
- Here we subtract the mean image
mean_image = np.mean(Xtr, axis=0).reshape(1, 784)
Xtr_rows -= mean_image
Xval_rows -= mean_image
Xte_rows -= mean_image
fig, ax = plt.subplots(figsize=(6, 6))
vis_utils.plot_image(ax, mean_image.reshape(28, 28))
1.2 Linear Classification¶
- First we will assume a linear score function, that is, a prediction that is a linear combination of inputs and model weights,
- For
MNIST, $D = 784$, and we need a weight for every pixel in an image.
- The choice of model weights will be inferred from the data in a procedure called training.
Stanford Computer Vision course--Convolutional Neural Networks for Visual Recognition http://cs231n.stanford.edu/
1.3 Model training¶
- Training involves computing a mathematical function that differentiates between observations from different classes--classifier.
- We first decide on a form for the function $f$ to take, then we optimise its parameters $\mathbf{w}$ over the dataset and a loss function, $\mathcal{L}$,
- The loss function measures how close the classification $f(\mathbf{x}_i ; \mathbf{w})$ of observations $\mathbf{x}_i$ is to the true value $y_i$.
Training consists of finding the weights that minimise the loss over the training set.
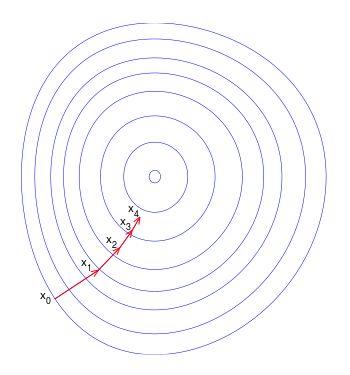
The most common procedure for optimising a convex differentiable function is known as gradient descent,
where $\alpha$ is referred to as the step size or learning rate. Thus, each iteration is a descent step, and we converge iteratively to a global minimum.
from src.linear_models import MultiSVM, SoftmaxRegression
# Perform bias trick
Xtr_rows = np.append(Xtr_rows, np.ones((Xtr_rows.shape[0], 1)), axis=1)
Xval_rows = np.append(Xval_rows, np.ones((Xval_rows.shape[0], 1)), axis=1)
Xte_rows = np.append(Xte_rows, np.ones((Xte_rows.shape[0], 1)), axis=1)
reg = 5e4
batch_size = 200
max_iters = 1500
learning_rate = 1e-7
model = MultiSVM(Xtr_rows, Ytr)
model.train(reg, batch_size, learning_rate, max_iters, Xval_rows, Yval)
1.4 Model Testing¶
num_test = Yte.shape[0]
predictions = [model.predict(Xte_rows[i]) for i in range(num_test)]
print('Error: %.02f%%' % (100 * (1 - float(sum(Yte == np.array(predictions))) / num_test)))
from src.vis_utils import plot_confusion_matrix
num_classes = 10
fig, ax = plt.subplots(figsize=(8, 6))
classes = ['zero', 'one', 'two', 'three', 'four', 'five', 'six', 'seven', 'eight', 'nine']
confusion_matrix = np.zeros((num_classes, num_classes), np.int32)
for i in range(len(predictions)):
confusion_matrix[Yte[i]][predictions[i]] += 1
plot_confusion_matrix(ax, confusion_matrix, classes, fontsize=15)
- Let's look at some of the model's mistakes
false = np.where(np.not_equal(Yte, predictions))[0]
idx = np.random.choice(false)
print('Prediction: %d\nTrue class: %d' % (predictions[idx], Yte[idx]))
fig, ax = plt.subplots(figsize=(6, 6))
vis_utils.plot_image(ax, Xte[idx][0:,:,0])
- In pixel-space, the model had moderate success in separating the image clusters.
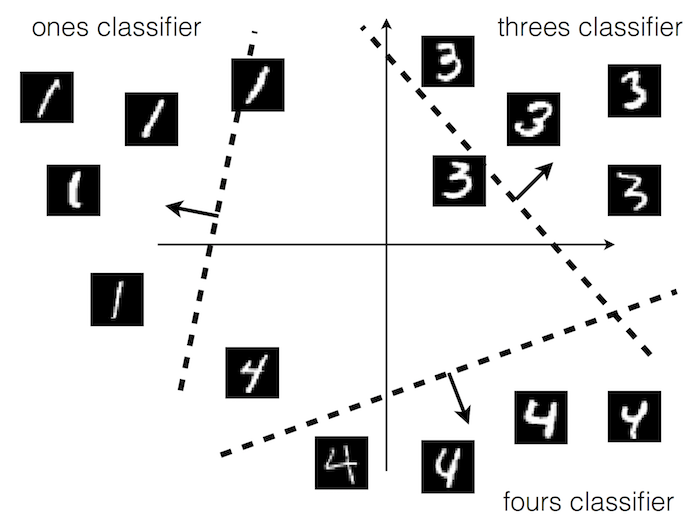
- The optimised weights are those generalising maximally over each of the class observations
- We can take each of the weight vectors and plot them as an image to visualise the template they have learned
fig = plt.figure(figsize=(8, 4))
vis_utils.plot_weights(fig, model.W[:-1,:], classes)
2. Deep Learning¶
Deep learning is characterised by the modeling of a hierarchy of abstraction in the input data. In the following we focus on applications to images, but note deep learning has seen great success in various fields from natural language processing to speech synthesis.
2.1 Features¶
- Features provide a representation of the objects we want to classify. Designing features is arguably the most difficult and most important aspect of machine learning.
- In the above we were operating purely on pixel features. One way we might improve is with feature engineering (expert knowledge), feature extraction (conventional techniques), feature selection, or dimensionality reduction.
- Another approach is to create non-linear transformations based on a kernel function (see kernel methods).
- Yet another approach is to build the feature learning into the model itself. This is the essence of representation or deep learning.
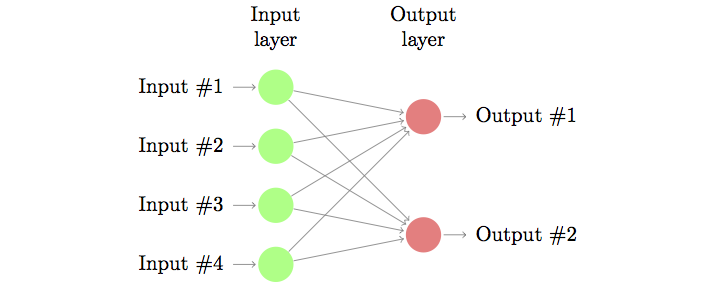
2.2 Artificial Neural Networks¶
- Neural networks model hidden layers between input and ouptut, passing through non-linear activation functions.
- Neural networks are particularly amenable to hierarchical learning, as hidden layers are easily stacked.
- (Loosely) inspired by the interaction of neurons in the human brain.
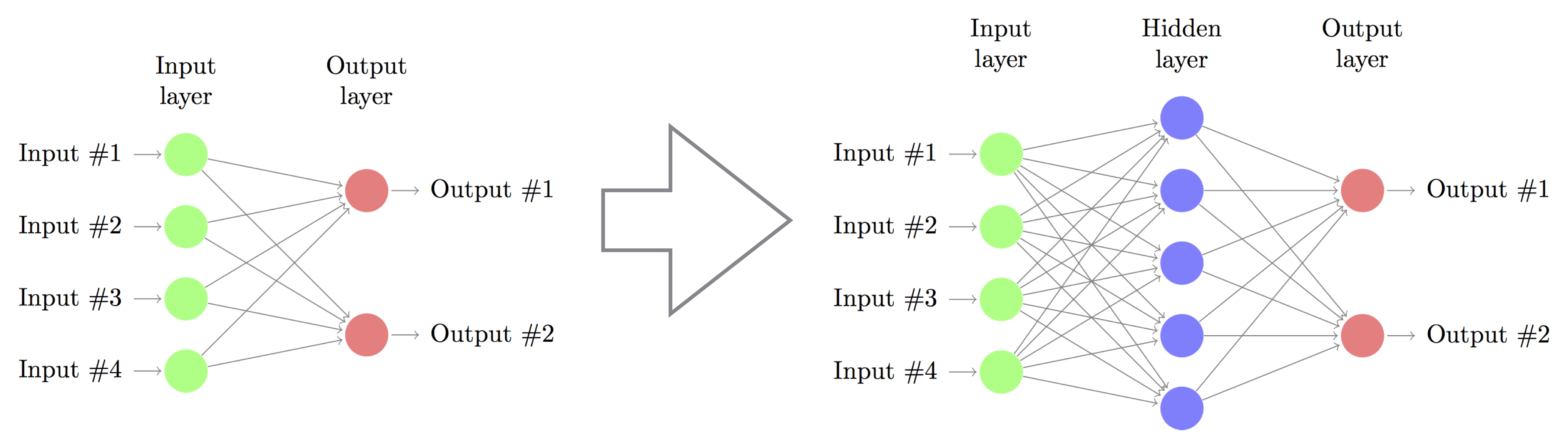
- Multiclass logistic regression:
where $\mathbf{W} \in \mathbb{R}^{K \times D}$ are the weights and $\mathbf{b} \in \mathbb{R}^{K \times 1}$ (sometimes incorporated into the weights--bias trick) and $\text{softmax}(x) = \frac{\exp(x)}{\sum_{x'}\exp(x')}$ generalises the sigma logistic function.
- Neural network (one hidden layer):
- Deeper network? Just keep stacking!
- No longer a linear model, outputs are non-linear combinations of inputs and model parameters.
- Non-convex, but still differentiable and trainable using gradient descent. Backpropagation algorithm computes the gradients by repeated application of the chain rule.
- Pros (+): Greater flexibility (universal approximator), built-in feature extraction.
- Cons (-): Harder to train (not convex), theory relatively underdeveloped.
2.3 Convolutional Neural Networks¶
Recall from signal processing, the convolution between two functions,
$$(f * g)(t) \triangleq \int_{-\infty}^{+\infty}f(\tau)g(t-\tau)d\tau$$In image processing, a convolution between an image $\mathbf{I}$ and kernel $\mathbf{K}$ of size $d \times d$ and centered at a given pixel $(x, y)$ is defined as,
$$(\mathbf{I} * \mathbf{K})(x, y) = \sum_{i = 1}^{d}\sum_{j = 1}^{d} \mathbf{I}(x + i -d/2, y + j - d/2) \times \mathbf{K}(i, j)$$The dimension $d \times d$ is referred to as the $\textit{receptive field}$ of the convolution.
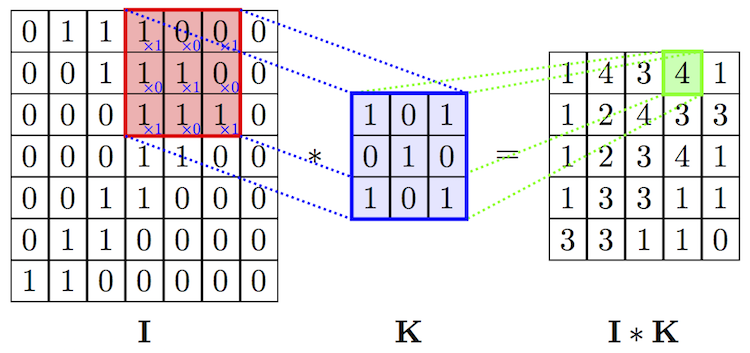

- Convolutional Neural Networks (CNN) are a type of feed-forward neural network wired so as to perform convolutions (image processing) on input data.
- Rather than one weight per pixel as before, the weights for a layer are restricted to a small, square kernel. This kernel is convolved with the local region at every pixel in the input image.
- A convolutional layer therefore produces an activation map, a new image where regions responding to the kernel are "activated" (give a high score).
- As such, feature extraction is built into the classifier and optimised w.r.t the same loss function (representation learning).
2.4 CNN architectures¶
- Convolutional Neural Networks (CNNs) comprise of a series of layers called an architecture. This usually conists of some convolutional layers for feature extraction, followed by traditional fully connected layers for classification.
- LeNet is the original network architecture of CNNs, introduced by Yann Lecun in the 90s.
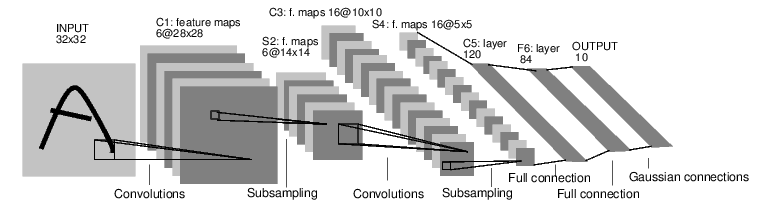
- $\mathbf{X} \in \mathbb{R}^{32 \times 32}$ are the input images and $\mathbf{H}_1 \in \mathbb{R}^{6 \times 28 \times 28}$, $\mathbf{H}_2 \in \mathbb{R}^{16 \times 10 \times 10}$ are (resp.) the 6 and 16 activation maps from the convolutional layers. The convolutional kernels are $\mathbf{K}^{(1)} \in \mathbb{R}^{6\times5\times5}$ and $\mathbf{K}^{(2)} \in \mathbb{R}^{16\times5\times5}$ i.e. 6 kernels of size $5\times5$ kernels for the first convolutional layer, 16 kernels of size $5\times5$ for the second. Multiple kernels are able to model different image motifs.
- Note that the reduction in size after each convolution is due to convolutions not being performed at the borders (aka valid convolution). It is, however, more common to pad the input images with zeros to allow convolution on every pixel, thereby preserving the input size. In our model, we have $28 \times 28$ inputs that will be zero-padded.
- The maxpool function scales down (downsamples) the input by selecting the greatest activation (most intense pixel) in each (typically) $2 \times 2$ block. Thus, each pooling layer halves the resolution. $\mathbf{P}_1 \in \mathbb{R}^{14 \times 14}$, $\mathbf{P}_2 \in \mathbb{R}^{5 \times 5}$ This is instrumental in forming hierarchical layers of abstraction.
- The first fully-connected layer, $\mathbf{F}_1 \in \mathbb{R}^{120}$ concatenates the 16 activation maps of size $5\times5$ vector. The rest of the network is like a traditional fully-connected network with $\mathbf{F}_2 \in \mathbb{R}^{84}$ and a $10 \times 1$ output layer.
- Though far from convex, the score function remains differentiable (just sums and products of weights interspersed with activations), and can be trained with gradient descent + backpropagation.
- A lot of deep learning research has been focused on improving learning: ReLU (more efficient activation function), Nestorov momentum/RMSprop/Adam (better optimisation), batch normalisation (weight stability), dropout (powerful regularisation).
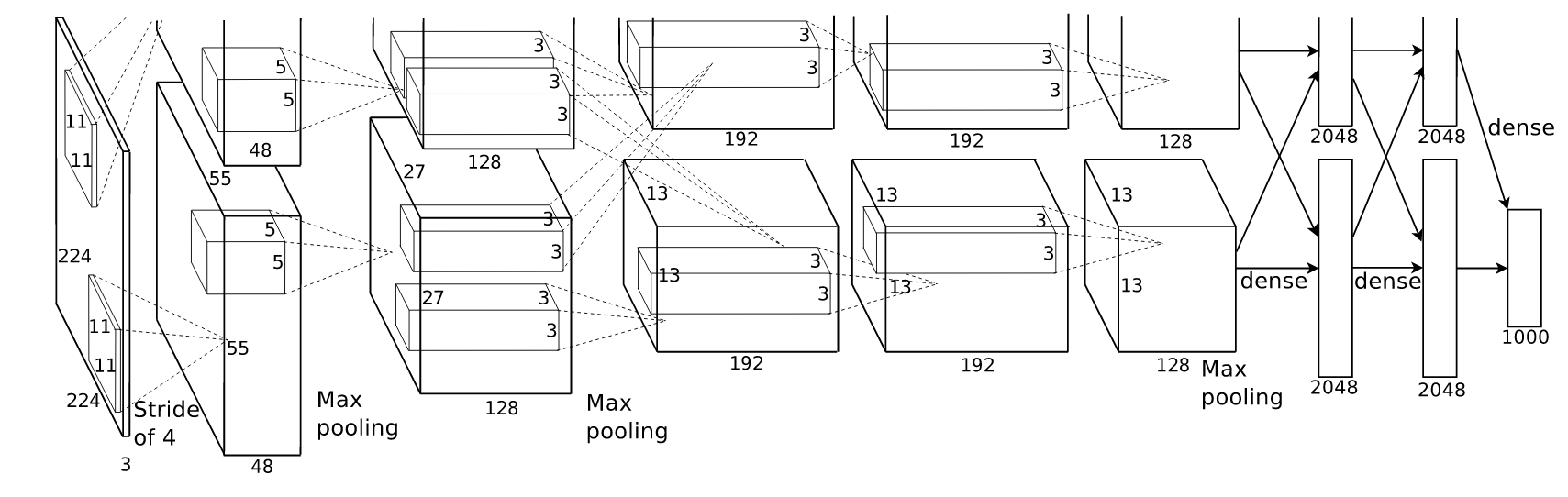
- CNNs were the breakout success in 2012 that won the ImageNet image classification challenge. AlexNet was a deep architecture that widened and deepened LeNet ($224 \times 224$) input images.
- The result was quickly followed by a paradigm shift in computer vision research, supplanting tailored feature extraction and reinstating neural networks in the state of the art.
- CNNs have since surmounted long-standing challenges in artificial intelligence (e.g. AlphaGo).
References:
- LeCun, Yann, Yoshua Bengio, and Geoffrey Hinton. "Deep learning." Nature 521.7553 (2015): 436-444.
- LeCun, Yann, et al. "Gradient-based learning applied to document recognition." Proceedings of the IEEE 86.11 (1998): 2278-2324.
- Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton. "Imagenet classification with deep convolutional neural networks." Advances in neural information processing systems. 2012.
2.5 Tensor Flow¶
- Python machine learning framework developed by Google Brain (deep learning group). Competes with $\texttt{Caffe}$, $\texttt{Theano}$, and $\texttt{Torch}$. Higher-level APIs exist such as $\texttt{Keras}$ and $\texttt{Lasagne}$.
- Originally proprietary, made open source (Apache 2.0) in late 2015
- Model is built into a computational graph
- Tensors (multi-dimensional arrays of data) are passed through a dataflow computational graph (stream processing paradigm).
- CNN code adapted from demo code in the official TensorFlow Docker image

First, we initialise our model. In TensorFlow, this consists of declaring the operations (and relationships thereof) required to compute the forward pass (from input to loss function) of the model (see src/cnn.py). Note that this is done in a declarative fashion, and it may be counter-intuitive that this code is only run once to initialise the computational graph. Actual forward passes are performed via a tf.Session() variable, with mini-batches passed through the graph to a nominal reference node (for example, the loss node). TensorFlow then knows how to backpropagate through each graph operation. This paradigm has its drawbacks, however, as it is highly verbose, and error traces are often opaque. PyTorch, a TensorFlow alternative, addresses this problem by keeping everything interpreted.
from src.cnn import ConvolutionalNeuralNetwork
nb_labels = 10
batch_size = 64
model = ConvolutionalNeuralNetwork(img_size=28, nb_channels=1, nb_labels=nb_labels)
2.6 Model Training¶
import tensorflow as tf
from src.utils import sample_batch, one_hot_encoding, error_rate
max_iters = 1500
with tf.Session() as sess:
saver = tf.train.Saver()
num_training = Xtr.shape[0]
batch = tf.Variable(0)
learning_rate = tf.train.exponential_decay(0.01,
batch * batch_size,
num_training,
0.95,
staircase=True)
optimizer = tf.train.MomentumOptimizer(
learning_rate, 0.9).minimize(model.loss, global_step=batch)
tf.global_variables_initializer().run()
for step in range(max_iters):
x_batch, y_batch = sample_batch(Xtr, Ytr, augment=False)
y_batch = one_hot_encoding(y_batch, nb_labels)
feed_dict = {model.X: x_batch, model.Y: y_batch}
_, l, lr, pred = sess.run(
[optimizer, model.loss, learning_rate, model.pred],
feed_dict=feed_dict)
if step % 100 == 0:
error = error_rate(pred, y_batch)
Yval_one_hot = one_hot_encoding(Yval, nb_labels)
print('Step %d of %d' % (step, max_iters))
print('Mini-batch loss: %.5f Error: %.5f Learning rate: %.5f' % (l, error, lr))
print('Validation error: %.1f%%' % error_rate(
model.pred.eval(feed_dict={model.X : Xval}), Yval_one_hot))
# save weights
saver.save(sess, '/tmp/model.ckpt')
2.7 Model testing¶
tf.reset_default_graph()
model = ConvolutionalNeuralNetwork(img_size=28, nb_channels=1, nb_labels=nb_labels)
saver = tf.train.Saver()
with tf.Session() as sess:
saver.restore(sess, '/tmp/model.ckpt')
pred, conv1, conv2 = sess.run([model.pred, model.conv1, model.conv2],
feed_dict={model.X : Xte[:1000]})
pred = np.argmax(pred, axis=1).astype(np.int8)
correct = np.sum(pred == Yte[:1000])
print('Test error: %.02f%%' % (100 * (1 - float(correct) / float(pred.shape[0]))))
classes = ['zero', 'one', 'two', 'three', 'four', 'five', 'six', 'seven', 'eight', 'nine']
confusion_matrix = np.zeros((num_classes, num_classes), np.int32)
for i in range(len(pred)):
confusion_matrix[Yte[i]][pred[i]] += 1
fig, ax = plt.subplots(figsize=(8, 6))
plot_confusion_matrix(ax, confusion_matrix, classes, fontsize=15)
- Current world record: 0.21% error from ensemble of 5 CNNs with data augmentation
Romanuke, Vadim. "Parallel Computing Center (Khmelnitskiy, Ukraine) represents an ensemble of 5 convolutional neural networks which performs on MNIST at 0.21 percent error rate.". Retrieved 24 November 2016."
- We can plot the activation maps of the following image as it passes through the network
img = Xtr[5]
fig, ax = plt.subplots(figsize=(6, 6))
vis_utils.plot_image(ax, Xte[0, :, :, 0])
- First, the 32 activations of the first convolutional layer ($28 \times 28$ px)
fig = plt.figure(figsize=(10, 5))
vis_utils.plot_activation_maps(fig, conv1, 4, 8)
plt.show()
Then, the 64 activations of the second convolutional layer ($14 \times 14$ px)
fig = plt.figure(figsize=(10, 10))
vis_utils.plot_activation_maps(fig, conv2, 8, 8)
plt.show()
- For a live demo of activations in deep networks, see the Deep Visualisation Toolbox (https://www.youtube.com/watch?v=AgkfIQ4IGaM)